本日學習的核心目標是為 RAG 系統建立檢索基礎。透過將 FAQ 問答知識庫轉換為向量並存入高效能資料庫 FAISS,使 Chatbot 具備「語義檢索」能力。
| 任務目標 | 核心技術 |
|---|---|
| 資料載入 | 從結構化 CSV 檔案中讀取 FAQ 資料。 |
| 文字向量化 (Embedding) | 使用 Sentence-Transformers 將問答內容轉換為高維度語義向量。 |
| 建立索引 | 使用 FAISS 建立高效的向量資料庫索引。 |
| 測試與驗證 | 實作檢索功能,驗證系統能否根據語義找到相似問答。 |
Embedding 是一種「文字 $\rightarrow$ 向量」的轉換方式,它將詞彙或句子轉換成高維度的數值向量。其關鍵在於:語義相近的文字,其向量在空間中的距離也越接近。這使得機器可以透過計算向量距離(如餘弦相似度或 L2 距離)來比較語義而非字面相似度。
FAISS (Facebook AI Similarity Search) 是一個專為高效相似度搜索設計的函式庫。在 RAG 架構中,FAISS 用於快速比較用戶查詢向量與知識庫中數百萬、數十億個向量的距離,從而找出最相關的 Top-K 文本片段。
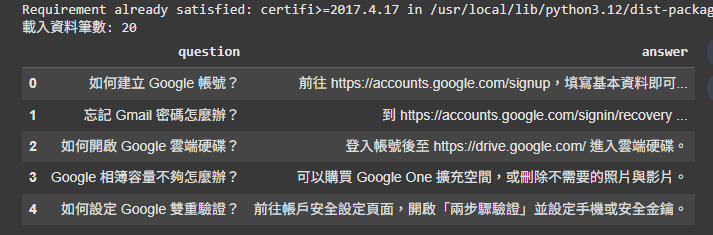
本階段確認安裝必要套件,並載入 Day 23 建立的 faq_data.csv。
# Day 24:建立知識向量資料庫
# 安裝必要套件(只需執行一次)
!pip install faiss-cpu sentence-transformers pandas
#載入 FAQ 資料
import pandas as pd
# 假設資料已正確命名為 faq_data.csv
data = pd.read_csv("faq_data.csv")
print("載入資料筆數:", len(data))
data.head()
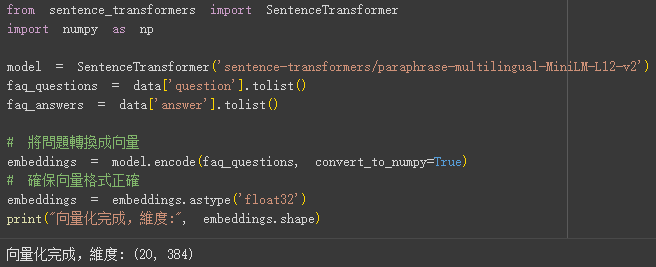
使用 sentence-transformers 模型(選擇 paraphrase-multilingual-MiniLM-L12-v2 適用於多語言語義)將 question 欄位的文本轉換為數值向量。
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
faq_questions = data['question'].tolist()
faq_answers = data['answer'].tolist()
# 將問題轉換成向量
embeddings = model.encode(faq_questions, convert_to_numpy=True)
# 確保向量格式正確
embeddings = embeddings.astype('float32')
print("向量化完成,維度:", embeddings.shape)
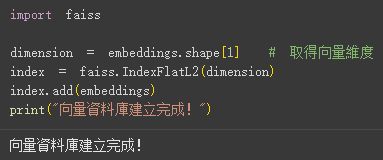
初始化 FAISS 索引並將所有向量加入。此處使用 IndexFlatL2,該索引使用 L2 距離(歐幾里得距離)進行搜索。
import faiss
dimension = embeddings.shape[1] # 取得向量維度
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
print("向量資料庫建立完成!")
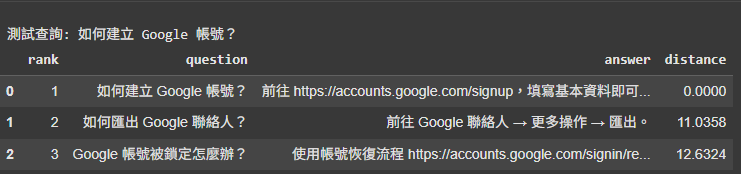
實作 search 函式,用於將查詢語句向量化,然後使用 FAISS 找到 Top-K 個最相似的問答。
#測試檢索
def search(query, top_k=3):
query_vec = model.encode([query]).astype('float32') # 查詢向量化
distances, indices = index.search(query_vec, top_k)
results = []
for i, idx in enumerate(indices[0]):
results.append({
"rank": i+1,
"question": faq_questions[idx],
"answer": faq_answers[idx],
# 距離(Distance)越小代表越相似
"distance": round(float(distances[0][i]), 4)
})
return pd.DataFrame(results)
# 範例測試
test_query = "如何建立 Google 帳號?"
print(f"\n測試查詢: {test_query}")
search(test_query)
| 項目 | 狀態 | 關鍵技術 |
|---|---|---|
| 知識庫載入 | 完成 | Pandas |
| 語義向量轉換 | 完成 | Sentence-Transformers |
| 向量資料庫建立 | 完成 | FAISS IndexFlatL2 |
| 語義檢索驗證 | 完成 | index.search() |
本日成功將靜態的 FAQ 資料轉換為動態、可語義檢索的向量資料庫。這一步是 RAG 系統中檢索 (Retrieval) 部分的核心。


 iThome鐵人賽
iThome鐵人賽